
Introduction
This is on the docupdate branch. We are updating this page
Caesar is an evolution of the Nero codebase, which is made more generic. In essence, Caesar receives classifications from the event stream (a Lambda script sends them to Caesars HTTP API).
For each classification, it runs zero or more extractors defined in the workflow to generate "extracts". These extracts specify information summarized out of the full classification.
Whenever extracts change, Caesar will then run zero or more reducers defined in
the workflow. Each reducer receives all the extracts, merged into one hash per
classification. The task of the reducer is to aggregate results from multiple
classifications into key-value pairs, where values are simple data types:
integers or booleans. The output of each reducer is stored in the database as a
Reduction.
Whenever a reduction changes, Caesar will then run zero or more rules defined
in the
workflow. Each
rule is a boolean statement that can look at values produced by reducers (by
key), compare. Rules support logic clauses like and / or / not. When the
rule evaluates to true, all of the effects associated with that rule will be
performed. For instance, an effect might be to retire a subject.
┏━━━━━━━━━━━━━━━━━━┓
┃ Kinesis ┃
┗━━━┳━━━━━━━━━━━━━━┛
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
│ EXTRACTS:
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ┐ ┌──────────────────┐ │ │
├──▶ Classification 1 ────┬───▶│ FlaggedExtractor │──────▶{flagged: true}
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ┘ │ └──────────────────┘ │ │
│ │ ┌──────────────────┐
│ └───▶│ SurveyExtractor │────┼─▶{raccoon: 1} │
│ └──────────────────┘
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ┐ ┌──────────────────┐ │ │
└──▶ Classification 2 ────┬───▶│ FlaggedExtractor │──────▶{flagged: false}
└ ─ ─ ─ ─ ─ ─ ─ ─ ┘ │ └──────────────────┘ │ │
│ ┌──────────────────┐
└───▶│ SurveyExtractor │────┼─▶{beaver: 1, raccoon: 1} │
└──────────────────┘
┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
REDUCTIONS: │
│ │ │
{ │
│ votes_flagged: 1, │ ┌──────────────────┐ │
votes_beaver: 1, ◀─────│ VoteCountReducer │◀─────────────────┘
│ votes_raccoon: 2 │ └──────────────────┘
}
│ │
┏━━━━━━━━━━━━━━━━┓
│ { │ ┌──────────────────┐ ┃Some script run ┃
swap_confidence: 0.23 ◀─────│ ExternalReducer │◀────HTTP API call────┃by project owner┃
│ } │ └──────────────────┘ ┃ (externally) ┃
┗━━━━━━━━━━━━━━━━┛
└ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
│
│
│ ┌──────────────────┐ POST ┏━━━━━━━━━━━━━━━━┓
└────────────────▶│ Rule │───/subjects/retire──▶┃ Panoptes ┃
└──────────────────┘ ┗━━━━━━━━━━━━━━━━┛
To make this more concrete, an example would be a survey-task workflow where:
- An extractor emits key-value pairs like
lion=1when the user tagged a lion in the image. - A reducer combines multiple classifications by adding up the lion counts,
emitting
lion=5, coyote=1 - A rule then checks
lion > 4, which returns true, and therefore Caesar retires the image.
Reducers can reduce across multiple subjects' extracts if the following is
included in the new subject's metadata (when uploaded to Panoptes): {
previous_subject_ids: [1234] }. Extracts whose subject ids match an id in that
array will be included in reductions for the new subject.
Usage
Caesar listens to classification events for workflows from the event stream. The tasks and subject sets connected to a specific workflow are configured via the project builder. To configure the data handling from classifications,
- Go to the Caesar Web UI and login.
- Click on "Workflows" and click "Add" and enter the workflow ID (you can find this in the Project Builder page)
- You can use the Extractors and Reducers to configure the extraction and reduction pipeline (as detailed below).
- Use the UI to configure your rules and effects as per the rules & effects docs.
Extracts
Extractors are tools that allow Caesar to extract specific data from the full classification output. Caesar (and the aggregations-for-caesar app) feature a collection of extractors for specific tasks.
Creating an extractor
To create an extractor:
- From the workflow summary page, click on the ‘Extractors’ tab. Press the ‘+Create Extractor’ button. You will be prompted to choose a type of extractor.
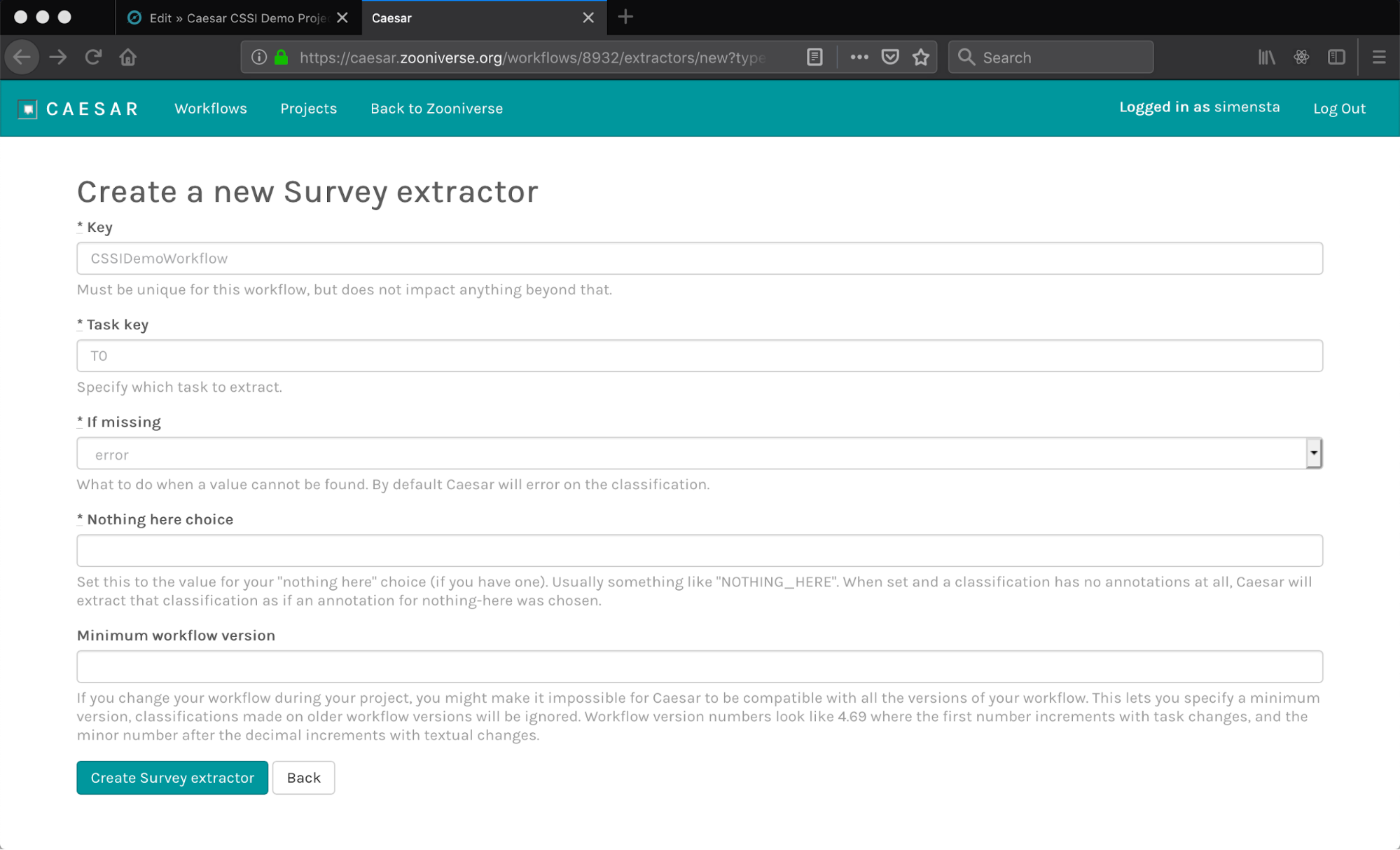
- Fill out the form for the new extractor. The generic fields for all extractors are:
- The
keyis an alpha-numeric identifier for this extractor that is unique to this workflow. Set a short, but descriptive string for this, e.g.,galaxy-type-extract. - The
task keyis the identifier of the task in the workflow. You can get this information from the project builder page (see image below)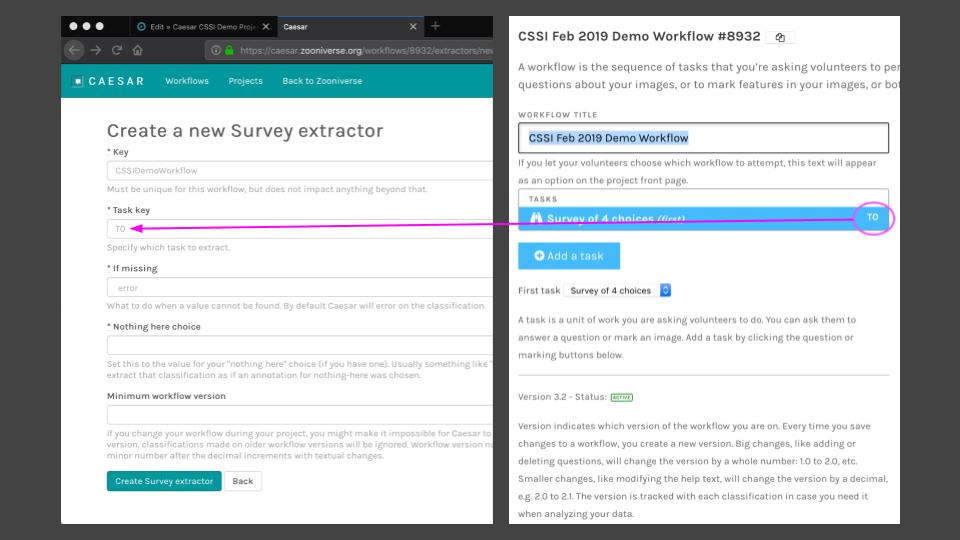
- The
if missingentry allows you to decide what should be done if the classification data is missing. The default choice is to error out of that extract. - The
minimum workflow versionprovides the choice to filter out early versions of the workflow, useful for limiting the data domain to post-development or post-launch classifications. - Each extractor will also have unique fields that need to be filled out, as detailed below.
- The
Extractor types
There are different types of extractors built into Caesar for specific tasks. The following sections shows the types of tools that each extractor supports.
Blank extractor
This extractor checks for whether a text entry (or some drawing tasks) in the classification is blank. The extractor outputs blank=true if the classification is empty or false instead.
Question extractor
Suited for question tasks, this extracts retrieves the index of the answer from the classification. Indices are C-style, i.e. the first index is "0".
Pluck field extractor
This extractor is used to retrieve a value from the classification/subject metadata. For example, if the filename of the subject is used during aggregation, this extractor would pass it as an extracted value.
Survey extractor
Shape extractor
External extractor
The External Extractor API passes the classification data to an external (HTTPS) URL, which responds with the extracted data in a JSON format. See the External API section below for more information.
Get extracts
GET /workflows/$WORKFLOW_ID/extractors/$EXTRACTOR_KEY/extracts?subject_id=$SUBJECT_ID HTTP/1.1
Content-Type: application/json
Accept: application/json
Authorization: Bearer $TOKEN
The above command returns JSON structured like this:
[
{
"classification_at": "2017-05-16T15:51:13.544Z",
"classification_id": 54376560,
"created_at": "2017-05-16T20:37:39.124Z",
"data": null,
"extractor_key": "c",
"id": 411083,
"subject_id": 458033,
"updated_at": "2017-05-16T20:37:39.124Z",
"user_id": 108,
"workflow_id": 4084
}
]
Extracts are pieces of information relating to a specific classification (and therefore to a specific subject as well).
Query Parameters
| Parameter | Default | Description |
|---|---|---|
| WORKFLOW_ID | null | Required · Specifies which workflow |
| SUBJECT_ID | null | Required · Specifies which subject |
| EXTRACTOR_KEY | null | Required · Specifies which extractor to fetch extracts from. |
Create & update extracts
Inserting and updating extracts happens through one and the same API endpoint, which performs an "upsert".
POST /workflows/$WORKFLOW_ID/extractors/$EXTRACTOR_KEY/extracts HTTP/1.1
Content-Type: application/json
Accept: application/json
Authorization: Bearer $TOKEN
{
"subject_id": 458033,
"classification_at": "2017-05-16T15:51:13.544Z",
"classification_id": 54376560,
"user_id": 108,
"data": {"PENGUIN": 1, "POLARBEAR": 4}
}
Body fields
The request body should be encoded as a JSON with the following fields:
| Parameter | Default | Description |
|---|---|---|
| subject_id | null | Required · Specifies which subject this extract is about |
| classification_id | null | Required · Specifies which classification this extract is about. May be omitted if known to be an update rather than a create. |
| classification_at | null | Required · Specifies what time the classification happened. This is used to sort extracts by classification time when reducing them. May be omitted if known to be an update rather than a create. |
| user_id | null | User that made the classification. null signifies anonymous. |
External API calls
When an ExternalExtractor or ExternalReducer is called the classification data is sent to the given URL (requires HTTPS) as JSON data. The external API then does the processing and returns a response to Caeser. The response from the external endpoint must be:
- 200 (OK)
- 201 (Resource Created)
- 202 (Processing Started)
- 204 (No Data)
All other responses will result in an error on Caesar. The data format for the classification data sent to an external extractor is shown below below:
Classification data format
Sample classification data
{
"id": 356374099,
"project_id": 16747,
"workflow_id": 19487,
"workflow_version": "20.23",
"subject_id": 67913886,
"user_id": 2245813,
"annotations": {
main task data here
},
"metadata": {
"started_at": "2021-08-31T19:24:09.056Z",
"finished_at": "2021-08-31T19:24:25.576Z",
"live_project": false,
"interventions": {"opt_in": true, "messageShown": false},
"user_language": "en",
"user_group_ids": [],
"workflow_version": "20.23",
"subject_dimensions": [{"clientWidth": 700, "clientHeight": 390, "naturalWidth": 700, "naturalHeight": 390}],
"subject_selection_state": {
"retired": false,
"selected_at": "2021-08-31T19:24:08.886Z",
"already_seen": false,
"selection_state": "normal",
"finished_workflow": false,
"user_has_finished_workflow": false
},
"workflow_translation_id": "48794"
},
"subject": {
"id": 67913886,
"metadata": {
subject metadata here
},
"created_at": "2021-08-31T19:24:26.032Z",
"updated_at": "2021-08-31T19:24:26.032Z"
}
}
The extractors gets the raw data from the classification. There are a set of standard fields that are common across all task types, but individual tasks contain specific data formats tailored to the data that they send. The common fields are:
id: The unique ID for the classificationproject_id: The ID for the project that this classification belongs toworkflow_id: The workflow attached to the classificationworkflow_version: The version for the workflow (is this something that project builders can set?)subject_id: The ID for the subject that was classifieduser_id: The unique ID for the user who classified this subjectannotations: Dictionary containing the actual classification data (differs based on the number of tasks, and the task types)metadata: Additional data for this classification. Most are standard HTTP headers, exceptstarted_at,finished_at: The start and times for this classificationlive_project: whether the project is liveinterventions: data on whether the volunteer was shown any feedback messagessubject_dimensions: The size of the subject (in pixels) on the screensubject_selection_state: Data about the subject's retirement state and whether it has been seen before.
subject: Data about the subject, includingid: The unique subject ID in the databasemetadata: Additional data about the subject (including filename, and whether it is agold_standarddata)
Task specific data
Example of annotation data
"annotations": {
"T0": [
{
"task": "T0",
"value": 0
}
],
"T1": [
{
"task": "T1",
"value": [
{
"x": 315.75,
"y": 151.96665954589844,
"toolIndex": 3,
"tool": 3,
"frame": 0,
"details": []
}
]
}
],
"T2": [
{
"task": "T2",
"value": "ffdddsssaaa"
}
]
}
The data for each task is passed into the annotations key in the JSON dictionary. The tasks are listed by the task name, with each entry containing information related to the type of task. The name of the task is stored in the task key, while the data associated with the task is stored in the value key. The value can vary from a simple text/number to a dictionary depending on the task type. In the example on the right, the first task is a question, the second is a point tool, and the third is a text tool.
Reducers
Reducers are used to compile a set of extracts together to create an aggregated result. For example, a set of answers from a question task can be combined to get the "best" answer (i.e. one with the most votes).
Creating Reducers
Reducers can be created from the "Reducers" tab in the workflow configure page. Like extractors, Caesar features a set of standard reducers, which are task dependent. To add a reducer to your workflow, click on the 'Create' button and choose from dropdown:
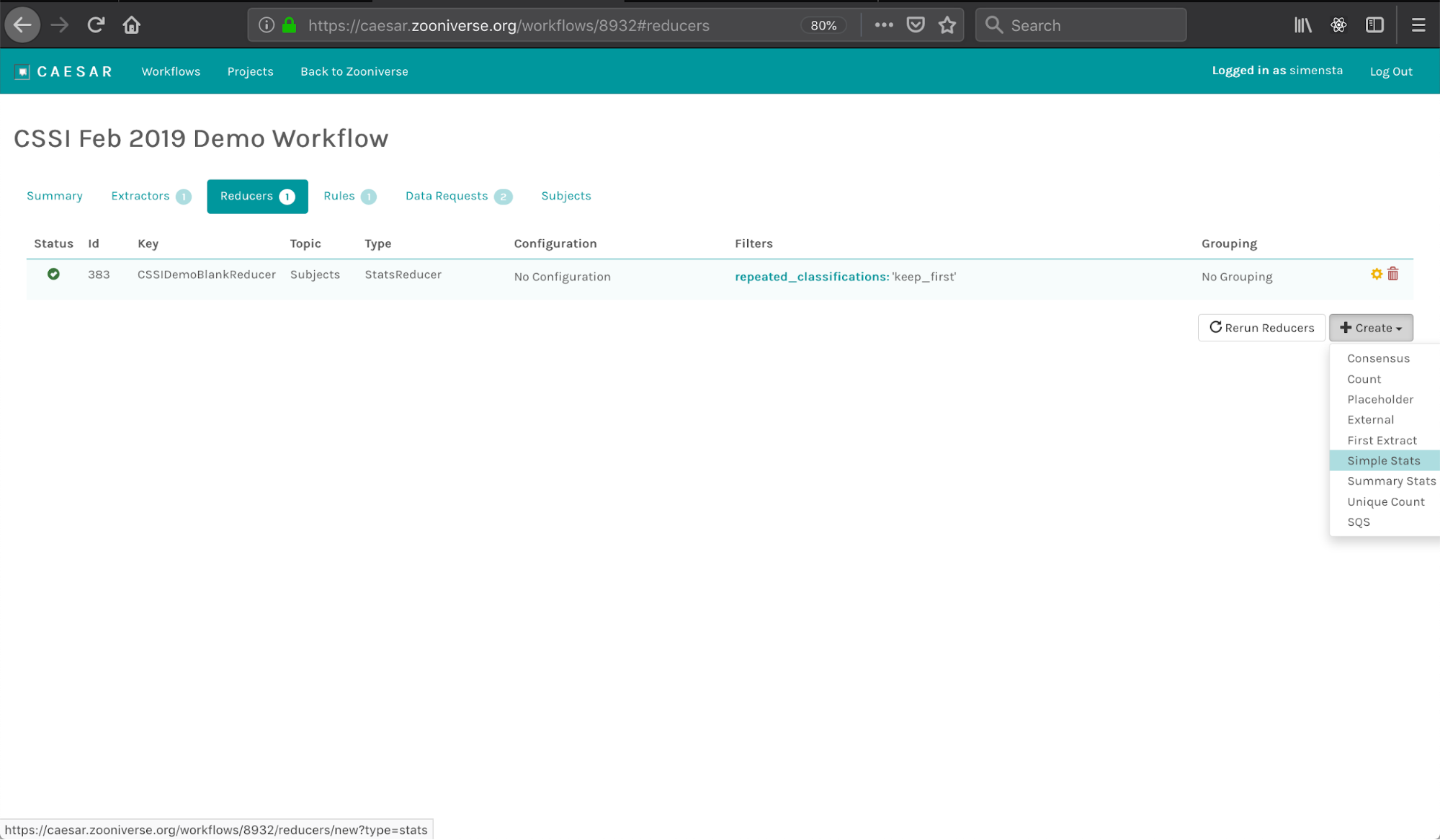
This will take you to a configuration window for that reducer:
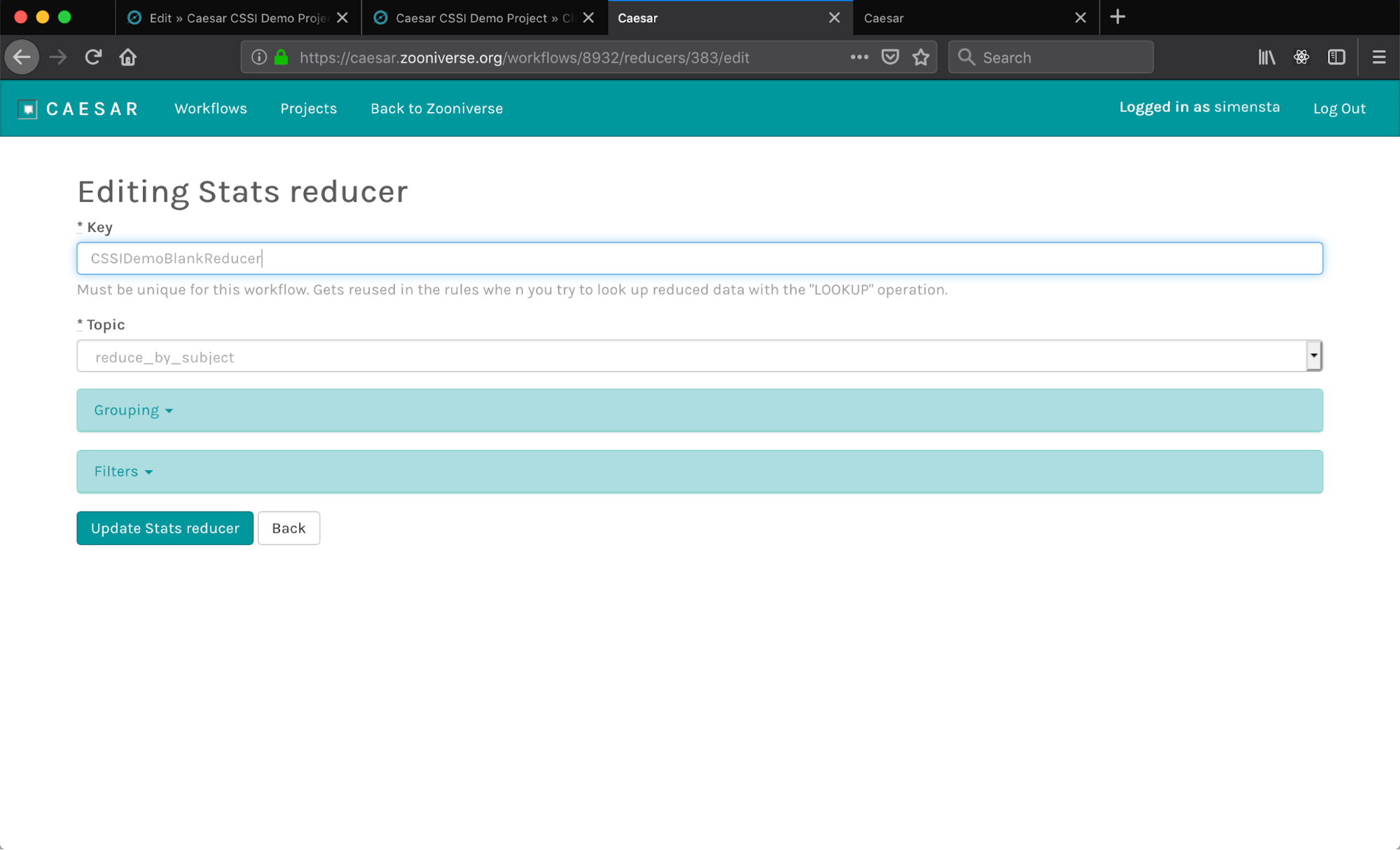
All reducers share the same set of keys, but configuring reducers can be tricky because they are flexible in so many different ways. These keys will be described below:
Key
This is the unique ID for this reducer. Use something that defines the functionality of the reducer. For example, a reducer that generates the consensus of a question task of galaxy morphology could be galaxy-morphology-consensus.
Topic
Extracts are always implicitly grouped before being combined. There are two different ways of doing this:
reduce_by_subject:
This filters all classifications by subject ID. Consequently, the aggregation will run on all classifications of a given subject. This is a useful way to get information about a specific subject.
reduce_by_user
This filters all classifications by user ID. Therefore, aggregation is done on all classifications done by that user in the current workflow. This is useful in getting statistics about specific users.
The default is reduce_by_subject.
Grouping
This is a confusing setting because extracts are already obviously grouped according to the topic. This allows an additional grouping pass, which, crucially, can be done on the basis of the value of a specified field. So to configure this, you need to set the name of the field to group by (in format extractor_key.field_name) and then a flag indicating how to handle when the extracts for a given classification are missing that field. The value of the grouping field will be reflected in the name of the group, stored in the subgroup field. The default behavior is not to perform this secondary grouping.
Filters
This tab allows you to filter what classifications are combined together. Caesar will search and retrieve all classifications based on the topic key defined above. In the filters tab, you can further refine which classifications in this subset you want to use (default: all), and which extracts to use for that classification. These keys are described below:
From/To
These keys allow you to subset the list of extracts to use, where from and to define the (zero-based) start and end index of the list of classifications. By default, Caesar will use all the retrieved extracts. For example, if you want everything from the 5th index to the end, set start=5 and end=-1.
Extractor Keys
This entry allows you to subset which extracts (defined in the extractor configuration) should be used for this reducer. Sometimes multiple extractors will be defined but a particular reducer only cares about or can only work with a particular type of extract. In this case, you can use the extractor keys property to restrict the extracts that are sent to this reducer. The format of this value is either a string (for a single extractor key) or an array of strings (for multiple extractors) of the extractor keys defined in the extractor configuration in the format ["extractor-key-1", "extractor-key-2", "extractor-key-3"]. The default, a blank string or a nil, sends all extracts.
Repeated classifications
This prescribes what Caesar should in case there are multiple classifications by the same user ID. keep_first is the default value, and Caesar will remove everything but the first time the user saw the subject. keep_last chooses the latest classification. keep_all will not delete any classifications. We recommend ‘keep_first’ unless you feel strongly that you’d prefer another of those options. It’s a rare event, but good to have a rule in place for it.
Training behavior
This configures what Caesar should do about training data (those with metadata keys #training_subjects = true). The default behaviour is to ignore_training where Caesar does not actively filter reduction inputs based on training metadata. This can be configured to work on training_only, where the reductions is only run on classifications which contain training subjects or the converse, where all training data is removed before aggregations (experiment_only). See training subject metadata for more info on training subjects.
Reduction Mode
This is probably the least understood part of configuring reducers. Briefly, the system offers two very different modes of performing reduction. These are:
default_reductionrunning_reduction
Default Reduction
In "default reduction" mode, each time a new extract is created, we fetch all of the other extracts for that subject (or user) and send them all to the reducer for processing. In cases where extracts are coming in very quickly, this can create some extra work fetching extracts, but is guaranteed to be free of race conditions because each new reduction will get a chance to reduce across all relevant extracts. This mode is much simpler and is preferred in almost every case. However, in the case where a given subject (or user) is likely to have thousands of associated extracts, it is recommended to use "running reduction" mode.
Running Reduction
"Running reduction" mode was created to support the Notes for Nature use case, where we are reducing across a user's entire classification history within a given project, which could run to tens of thousands of items for power users. In this use case, fetching all 10,000 extracts each time a new extract is created is impractical and the operations we want to perform are relatively simple to perform using only the new extracts created in a given extraction pass.
When a reducer is configured for running reduction, each time a new classification produces new extracts, the reducer is invoked with only those new extracts. Any additional information it would need in order to correctly compute the reduction should be present in a field on the reduction, called a store. With the new extracts and the store, the reducer will compute an updated value and update its store appropriately. However, this can't be done in a multithreaded way or else the object might be available while in an inconsistent state (example: its store has been updated but its value has not). Accordingly, we use optimistic locking semantics, so that we prefetch all possible relevant extracts and reductions before reducing and throw a sync error if the object versions don't match when we try to save. Further, we need to avoid updating the reduction multiple times with the same extract, which is not a concern with running reduction. Therefore, this mode populates a relation tracking which extracts have been incorporated into which reductions. Between this and the synchronization retries, there is considerable added complexity and overhead compared to default reduction mode. It's not recommended to use running reduction mode with external reducers, because the added complexity of writing reducers that reduce from a store.
Reduction Mode Example
Reducer types
Caesar features a set of standard reducers that are useful for most projects. These are described below:
Given the following extracts
extract_list = [
{"data":
{"ZEBRA": 1}
},
{"data":
{"ZEBRA": 1}
},
{"data":
{"AARDVARK": 1}
},
{"data":
{"ZEBRA": 1}
}
]
The consensus, count and simple stats reducers will output
consensus_reducer_return = {
"most_likely": "ZEBRA",
"num_votes": 3,
"agreement": 0.75
}
Consensus
Uses the counting hash to summate the unique extracted key:value pairs.
The reducer will select the key with the highest summated value as the most likely (most_likely) answer.
It will also return the total number of votes (num_votes) for this most_likely answer.
Finally it will return an agreement value which is the num_votes/ number of all submitted classifications.
An example is shown on the right.
count_reducer_return = {
"classifications": 4,
"extracts": 4
}
Count
The count reducer will simply return a count of the number of classifications
(accounting for the rules set up for repeated classifications). The classifications entry shows
the number of classifications, and the extracts key shows the number of corresponding extracts.
simple_stats_reducer_return = {
"ZEBRA": 4,
"AARDVARK": 1
}
Simple Stats
Summates the extracted classification annotations key:value pair data. This reducer relies on the annotation data being in the correct format for summation, e.g. [["ZEBRA", 1]] Please note if the annotation shape doesn't include a summatable value, e.g. the 1 in above example, this reducer will require an aligned extractor to configure the key value to be summated.
Note this reducer can count True and False values as well, True increments by 1, False does note increment
First Extract
This reducer will return the output of the first extract in the list of extracts. This is useful when extracting data that is common to the subject or the user (e.g., subject metadata).
SQS
Setting up an SQS reducer instructs Caesar to send the output of our extractor to an AWS SQS queue. We can then use remote aggregation code to consume and process those extracts asynchronously and without having to maintain a dedicated server to accept extracted data. The reducer needs to be configured (through the admin console) with the URL and name of an AWS SQS queue that will receive and temporarily store the classifications from the workflow
Rectangle
This reducer is used to cluster extracts from the Rectangle tool. It uses the DBSCAN algorithm to aggregate the shapes together.
External
This is similar to an external extractor, and is configured by providing a URL (requires HTTPS) that serves as an endpoint for the extractor data from Caesar.
Reduction Mode Examples
This example is to clarify the difference between how default reduction and running reduction work. Imagine the extract from each classification produces a number from 0 to 10 and the reducer computes the average of these numbers.
The same extracts are processed by each reducer in the same order and we illustrate the changing values in the system as they arrive. For clarity, the values of extracts are indicated in bold.
Default Reduction
| Extract ID | Extract Value | Extracts to reducer | Store Value In | Calculation | Store Value | Items in Association |
|---|---|---|---|---|---|---|
| 1 | 5 | 1 | nil | 5/1 | nil | 0 |
| 2 | 3 | 1, 2 | nil | (5+3)/2 | nil | 0 |
| 2 | 3 | 1, 2 | nil | (5+3)/2 | nil | 0 |
| 3 | 4 | 1, 2, 3 | nil | (5+3+4)/3 | nil | 0 |
Running Reduction
| Extract ID | Extract Value | Extracts to reducer | Store Value In | Calculation | Store Value | Items in Association |
|---|---|---|---|---|---|---|
| 1 | 5 | 1 | nil | (0*0+5)/(0+1) | 1 | 1 |
| 2 | 3 | 2 | 1 | (5*1+3)/(1+1) | 2 | 2 |
| 2 | 3 | nil | N/A | N/A | 2 | 2 |
| 3 | 4 | 3 | 2 | (4*2+4)/(2+1) | 3 | 3 |
Points of Note
Note that in default reduction mode, re-reduction is always triggered, regardless of whether an extract is being processed twice. Also notice that each computation in default reduction consumes all of the extracts. We calculate an average by summing together the values of all of the extracts and then dividing by the number of extracts.
In running reduction, on the other hand, the store keeps a running count of how many items the reducer has seen. This store, with the previous value of the reduction, can be used to compute the new average using only the new value by using the formula ((old average * previous count) + new value)/(old count + 1) and the store can be updated with the new count (old count + 1).
When using running reducers for performance reasons, please keep in mind that the performance benefits of running reduction are only realized if every reducer for that reducible is executed in running mode. The primary advantage of running reduction is that it eliminates the need to load large numbers of extracts for a given subject or user.
Subject Metadata
Caesar can reflect on several attributes in a subject's metadata to know how to perform certain actions.
#training_subject:
- Boolean. If true, subject is a training subject.
- Used to funnel training subjects to a separate reduction pathway.
- Example: TESS user weighting
- ExtractFilter allows filtering by training behavior.
- To use: set a filter on reducer to include:
training_behavior: training_onlyorexperiment_only - See Subject#training_subject? and Filters::FilterByTrainingBehavior for use.
#previous_subject_ids:
- Array of Zooniverse subject ids
- Subjects whose ids are included in array will be passed by RunsReducers to FetchExtractsBySubject
- Used to indicate that one or more prior subjects' extracts should be included when reducing a new subject.
- Example: TESS takes a new image of the same piece of the sky as a previous subject on a subsequent pass. The previous subject's Zooniverse id is included in the subject metadata and all extracts for both subjects are included in the new subject's reduction.
- See Subject#additional_subject_ids_for_reduction for use.
Rules
A workflow can configure one or many rules. Each rule has a condition and one or more effects that happen when that condition evaluates to true. Conditions can be nested to achieve complicated if statements.
Rules may pertain to either subjects or users. Rules have an evaluation order that can be set in the database if need be, and then rules can either be all evaluated or evaluated until the first true condition is reached.
Conditions
The condition is a single operation, but some types of operations can be nested. The general syntax is like if you'd write Lisp in JSON. It's always an array with as the first item a string identifying the operator. The other values are operations in themselves: [operator, arg1, arg2, ...].
["lt", operation, operation, ...]- Performs numerical comparison. You can specify more than two arguments, and it will evaluate asa < b < c < d.["lte", operation, operation, ...]- Performs numerical comparison. You can specify more than two arguments, and it will evaluate asa <= b <= c <= d.["gt", operation, operation, ...]- Performs numerical comparison. You can specify more than two arguments, and it will evaluate asa > b > c > d.["gte", operation, operation, ...]- Performs numerical comparison. You can specify more than two arguments, and it will evaluate asa >= b >= c >= d.["eq", operation, operation, ...]- Performs numerical comparison. You can specify more than two arguments, and it will evaluate asa == b == c == d.["const", value]- Always returns the configured value.["lookup", key]- Look up a reduction value by the given key.["not", operation]- Negates the operation["and", operation, operation, ...]- Returns true if all of the given operations evaluate to logical true["or", operation, operation, ...]- Returns true if any of the given operations evaluates to logical true
Sample conditions
If one or more vehicles is detected
From the console:
ruby
SubjectRule.new
workflow_id: 123,
condition: ['gte', ['lookup', 'survey-total-VHCL'], ['const', 1]],
row_order: 1
Input into UI:
json
["gte", ["lookup", "survey-total-VHCL"], ["const", 1]]
If the most likely identification is "HUMAN"
From the console:
ruby
SubjectRule.new
workflow_id: 123,
condition: ['gte', ['lookup', 'consensus.most_likely', ''], ['const', 'HUMAN']],
row_order: 3
Input into UI:
json
["gte", ["lookup", "consensus.most_likely", ""], ["const", "HUMAN"]]
Effects
Each rule can have one or more effects associated with it. Those effects will be performed when that rule's condition evaluates to true. Subject Rules have effects that affect subjects (and implicitly receive subject_id as a parameter) and User Rules have effects that affect users (user_id).
Subject Rule Effects
| effect_type | config Parameters |
Effect Code |
|---|---|---|
retire_subject |
reason (string)* |
Effects::RetireSubject |
add_subject_to_set |
subject_set_id (string) |
Effects::AddSubjectToSet |
add_subject_to_collection |
collection_id (string) |
Effects::AddSubjectToCollection |
external_effect |
url (string)** |
Effects::ExternalEffect |
* Panoptes API validates reason against a list of permitted values. Choose from blank, consensus, or other
** url must be HTTPS
User Rule Effects
| effect_type | config Parameters |
Effect Code |
|---|---|---|
promote_user |
workflow_id (string) |
Effects::ExternalEffect |
Sample Effects
Retire a subject
From the console:
SubjectRuleEffect.new
rule_id: 123,
effect_type: 'retire_subject',
config: { reason: 'consensus' }
In the UI:
These can be configured in the UI normally, there's nothing complicated like the condition field.
Promote a user to a new workflow
From the console:
ruby
UserRuleEffect.new
rule_id: 234,
effect_type: 'promote_user',
config: { 'workflow_id': '555' }
How to do SWAP
In Panoptes, set
workflow.configurationto something like:
{"subject_set_chances": {"EXPERT_SET_ID": 0}}
In Caesar, set the workflow like so:
{
"extractors_config": {
"who": {"type": "who"},
"swap": {"type": "external", "url": "https://darryls-server.com"} # OPTIONAL
},
"reducers_config": {
"swap": {"type": "external"},
"count": {"type": "count"}
}
"rules_config": [
{"if": [RULES], "then": [{"action": "retire_subject"}]}
]
}
When you detect an expert user, update their probabilities like this:
POST /api/project_preferences/update_settings?project_id=PROJECT_ID&user_id=USER_ID HTTP/1.1
Host: panoptes-staging.zooniverse.org
Authorization: Bearer TOKEN
Content-Type: application/json
Accept: application/vnd.api+json; version=1
{
"project_preferences": {
"designator": {
"subject_set_chances": {
"WORKFLOW_ID": {"SUBJECT_SET_ID": 0.5}
}
}
}
}
And store expert-seenness in Caesar so that you can use it in the rulse
POST /workflows/WORKFLOW_ID/reducers/REDUCER_KEY/reductions HTTP/1.1
Host: caesar-staging.zooniverse.org
Authorization: Bearer TOKEN
Content-Type: application/json
Accept: application/json
{
"likelyhood": 0.864,
"seen_by_expert": false
}
This document is a reference to the current state of affairs on doing SWAP on the Panoptes platform (by which we mean the Panoptes API, Caesar, and Designator).
To do SWAP, one must:
Track the confusion matrix of users. We currently expect this to be done by some entity outside the Panoptes platform. This could be a script that runs periodically on someone's laptop, or it can be an external webservice that gets classifications streamed to it in real-time by Caesar (this is what Darryl is doing). We don't currently have a good place to store the confusion matrix itself inside the Panoptes platform. But, if the matrix identifies an expert classifier, post that into Panoptes under the
project_preferencesresource (API calls explained in later section)Calculate the likelyhood of subjects. This is done in the same place that also calculates the confusion matrices. The resulting likelyhood should be posted into Caesar as a
reduction.Retire subjects when we know the answer. By posting the likelyhood into Caesar, we can set rules on it. For instance:
IF likelyhood < 0.1 AND classifications_count > 5 THEN retire()IF likelyhood > 0.9 AND classifications_count > 5 THEN retire()IF likelyhood > 0.1 AND likelyhood < 0.9 AND not seen_by_expert AND classifications > 10 THEN move to expert_set
When Caesar moves subjects into an expert-only subject set, Designator can then serve subjects from that set only to users marked as experts by the
project_preferences. Designator is all about serving subjects from sets with specific chances, which means that we avoid the situation where experts only ever see the really hard subjects by mixing e.g. 50% hard images with 50% "general population".
Errors
The Kittn API uses the following error codes:
| Error Code | Meaning |
|---|---|
| 400 | Bad Request -- Your request sucks. |
| 401 | Unauthorized -- Your API key is wrong. |
| 403 | Forbidden -- The kitten requested is hidden for administrators only. |
| 404 | Not Found -- The specified kitten could not be found. |
| 405 | Method Not Allowed -- You tried to access a kitten with an invalid method. |
| 406 | Not Acceptable -- You requested a format that isn't json. |
| 410 | Gone -- The kitten requested has been removed from our servers. |
| 418 | I'm a teapot. |
| 429 | Too Many Requests -- You're requesting too many kittens! Slow down! |
| 500 | Internal Server Error -- We had a problem with our server. Try again later. |
| 503 | Service Unavailable -- We're temporarily offline for maintenance. Please try again later. |